Transient Plans¶
Sometimes similar looking queries can have very different execution plans. We have seen this so far by modifying the population predicate: in Example 8, by specifying population > 500M a different index was chosen from specifying >5M.
This happens quite frequently in production environments, where portions of a query may be generated from user-input [1]:
- Specifying a date range of between now and yesterday on a data set with months of data will likely use an index on a date column. Specifying between now and last year may not.
- Finding records WHERE
is_deleted=1may filter out a number of records, and be quite suitable for indexing. Similarly, WHEREis_deleted=0may not.
This is expected behavior, and is the result of gathering statistics (mentioned earlier under ‘Metadata and Statistics’). The following table shows how the relative cost of indexes changes as population and continent are changed.
| p>5M c=’Asia’ | p>5M c=’Antarctica’ | p>50M, c=’Asia’ | p>50M c=’Antarctica’ | p>500M, c=’Asia’ | p>500M c=’Antarctica’ | |
|---|---|---|---|---|---|---|
| p | 152.21 | 152.21 | 34.61 | 34.61 | 3.81 | 3.81 |
| c | 28.20 | 6.00 | 28.20 | 6.00 | 28.20 | 6.00 |
| c,p | 24.83 | 2.41 | 16.41 | 2.41 | 3.81 | 2.41 |
| p,c | 152.21 | 152.21 | 34.61 | 34.61 | 3.81 | 3.81 |
| table scan | 53.80 | 53.80 | 53.80 | 53.80 | 53.80 | 53.80 |
- The table scan has a relatively fixed cost, since it is always just looking at every row in the table.
- The cost of using the
porcindex changes as the input value is able to filter more effectively (there are fewer countries in Antarctica, and fewer countries with a greater population). - A composite index on
c,pis relatively effective at reducing the cost of most queries. - The costs of the
pandp,cindex are identical for reasons previously explained. Thep,cindex will only use thepportion of the index due to the left-range. - In this data set, there are four countries in Antarctica all with a population of zero. The composite index on
c,presults in the lowest cost query because there are zero results.
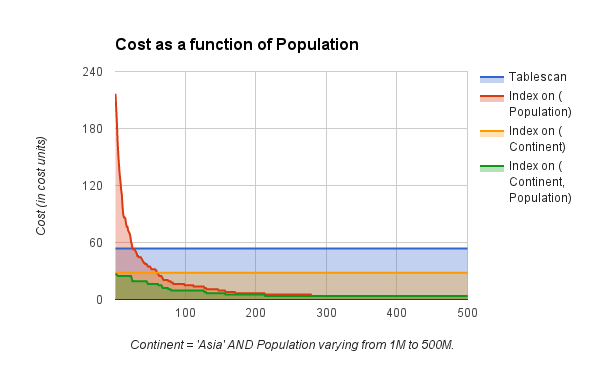
This information can also be represented visually. Notice that the table scan and ref access on continent has a fixed cost, and that the composite index on (Continent, Population) starts at the same cost as the ref access on continent when population is not very selective. As the population count is increased it becomes more selective.
If the composite index was not very effective you would see a scenario where it would follow closer to the cost of one of the individual indexes (either population or continent). In the end, since all countries with a population >300M are in Asia, the selectivity is not any better than an index on just population.
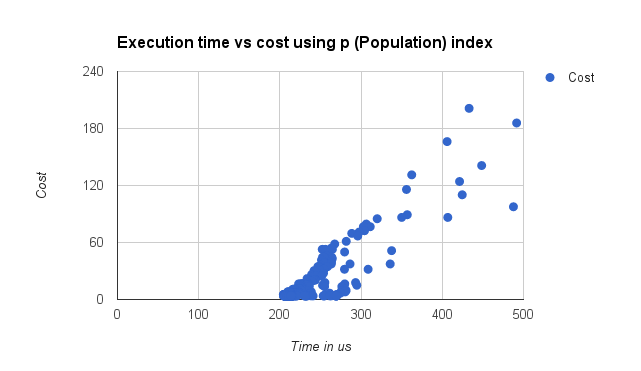
The following visualization takes the median runtime of 100 executions forcing the index to p and varying the Population range (from WHERE population > 1M to WHERE population > 500M). The execution time was taken from performance_schema.events_statements_history_long, and converted to microseconds (μs). I suspect that because the data set is small, and that because there are very few countries with a small population there is some clustering of the execution time where the same distinct set of pages are accessed. But none-the-less there is some correlation.
Tip
These visualizations are highly data distribution dependent. As you examine the sample data set, you may notice that there are some inaccuracies. The data is from Statistics Finland (c.1990s) and has not been uniformly updated.
| [1] | Depending on the spectrum of queries, both of these examples may also be better served by partitioning, rather than indexing. |