Covering Indexes¶
A covering index is a special type of composite index, where all of the columns exist in the index. In this scenario, MySQL is able to apply an optimization where it just returns the data from the index without accessing table rows.
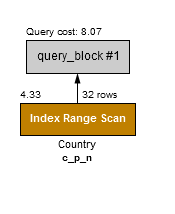
Consider the case that instead of saying SELECT * FROM Country, we only need to know the Name of the Country which meets the conditions population > 5M and continent='Asia'. As shown in Example 12, an index on c_p_n (Continent,Population,Name) can use the first two columns for filtering rows, and return the value from the third column.
Example 12: A covering index on c_p_n
ALTER TABLE Country ADD INDEX c_p_n (Continent,Population,Name);
EXPLAIN FORMAT=JSON
SELECT Name FROM Country WHERE continent='Asia' and population > 5000000;
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "8.07" # The cost is reduced by 67%
},
"table": {
"table_name": "Country",
"access_type": "range",
"possible_keys": [
"p",
"c",
"p_c",
"c_p",
"c_p_n"
],
"key": "c_p_n",
"used_key_parts": [
"Continent",
"Population"
],
"key_length": "5",
"rows_examined_per_scan": 32,
"rows_produced_per_join": 15,
"filtered": "100.00",
"using_index": true, # Using index means "covering index"
"cost_info": {
"read_cost": "1.24",
"eval_cost": "3.09",
"prefix_cost": "8.07",
"data_read_per_join": "3K"
},
"used_columns": [
"Name",
"Continent",
"Population"
],
"attached_condition": "((`world`.`Country`.`Continent` = 'Asia') and (`world`.`Country`.`Population` > 5000000))"
}
}
}
The use of a covering index is denoted in EXPLAIN by the output "using_index": true. Covering indexes are an under-appreciated optimization. Many practitioners incorrectly assume a covering index to be “half the cost” because the index is used, but the table rows are not touched. In Example 12 we can see that the cost is approximately 1/3rd of the cost compared to the non-covering index shown in Example 11.
In production environments covering indexes may have a better memory fit than other queries because of the clustering effect of indexes. This is to say that if the secondary index being accessed does not correlate [1] with the clustered index (primary key) there may be a much higher number of clustered key pages which need to be accessed.
| [1] | By correlate I mean “roughly follow the same order”. For example a secondary index on inserted timestamp will correlate highly to an auto_increment primary key. The indexes on population and continent are unlikely to correlate to the primary key, which is a three letter country code. |