Sorting¶
MySQL has four ways to return results in sorted order, which may be required as part of an ORDER BY or GROUP BY (without ORDER BY NULL). EXPLAIN will show if the data requires a sort operation, but it will not list which sort algorithm is used. This information is available in OPTIMIZER_TRACE. The four ways to return results sorted are as follows:
Via an Index. B+tree indexes are maintained in sorted order, so some
ORDER BYqueries do not require sorting at all.Via a Priority Queue. An
ORDER BYwith a small limit may be able to store the complete result set in a temporary buffer. As an example, consider the query:SELECT * FROM Country IGNORE INDEX (p, p_c) ORDER BY population LIMIT 10;
This query will table scan, and keep a buffer of the rows with the 10 highest populations. As newer rows are identified with higher populations, earlier rows can be pushed out of the priority queue.
Via the Alternative Sort Algorithm. This algorithm is used if no TEXT or BLOB columns are present. It is defined in the MySQL manual [1] as:
- Read the rows that match the WHERE clause.
- For each row, record a tuple of values consisting of the sort key value and the additional fields referenced by the query.
- When the sort buffer becomes full, sort the tuples by sort key value in memory and write it to a temporary file.
- After merge-sorting the temporary file, retrieve the rows in sorted order, read the required columns directly from the sorted tuples
Via the original sort algorithm. This algorithm is used when
TEXTorBLOBcolumns are present. It is defined in the MySQL manual [1] as:- Read all rows according to key or by table scanning. Skip rows that do not match the WHERE clause.
- For each row, store in the sort buffer a tuple consisting of a pair of values (the sort key value and the row ID).
- If all pairs fit into the sort buffer, no temporary file is created. Otherwise, when the sort buffer becomes full, run a qsort (quicksort) on it in memory and write it to a temporary file. Save a pointer to the sorted block.
- Repeat the preceding steps until all rows have been read.
- Do a multi-merge of up to MERGEBUFF (7) regions to one block in another temporary file. Repeat until all blocks from the first file are in the second file.
- Repeat the following until there are fewer than MERGEBUFF2 (15) blocks left.
- On the last multi-merge, only the row ID (the last part of the value pair) is written to a result file.
- Read the rows in sorted order using the row IDs in the result file. To optimize this, read in a large block of row IDs, sort them, and use them to read the rows in sorted order into a row buffer. The row buffer size is the
read_rnd_buffer_sizesystem variable value. The code for this step is in thesql/records.ccsource file.
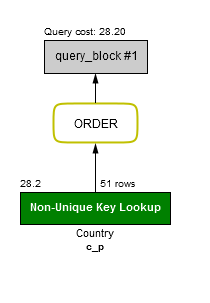
Example 30: A sort is provided by an index
EXPLAIN FORMAT=JSON
SELECT * FROM Country WHERE continent='Asia' ORDER BY population;
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "34.10"
},
"ordering_operation": {
"using_filesort": false, # The sort is provided by the c_p index
"table": {
"table_name": "Country",
"access_type": "ref",
"possible_keys": [
"c",
"c_p"
],
"key": "c_p",
"used_key_parts": [
"Continent"
],
"key_length": "1",
"ref": [
"const"
],
"rows_examined_per_scan": 51,
"rows_produced_per_join": 51,
"filtered": "100.00",
"index_condition": "(`world`.`Country`.`Continent` <=> 'Asia')",
"cost_info": {
"read_cost": "23.90",
"eval_cost": "10.20",
"prefix_cost": "34.10",
"data_read_per_join": "13K"
},
"used_columns": [
"Code",
"Name",
"Continent",
"Region",
"SurfaceArea",
"IndepYear",
"Population",
"LifeExpectancy",
"GNP",
"GNPOld",
"LocalName",
"GovernmentForm",
"HeadOfState",
"Capital",
"Code2"
]
}
}
}
}
Example 31: OPTIMIZER_TRACE showing the priority queue used
SET OPTIMIZER_TRACE="ENABLED=on";
SELECT * FROM Country IGNORE INDEX (p, p_c) ORDER BY population LIMIT 10;
SELECT * FROM information_schema.optimizer_trace\G
{
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `Country`.`Code` AS `Code`,`Country`.`Name` AS `Name`,`Country`.`Continent` AS `Continent`,`Country`.`Region` AS `Region`,`Country`.`SurfaceArea` AS `SurfaceArea`,`Country`.`IndepYear` AS `IndepYear`,`Country`.`Population` AS `Population`,`Country`.`LifeExpectancy` AS `LifeExpectancy`,`Country`.`GNP` AS `GNP`,`Country`.`GNPOld` AS `GNPOld`,`Country`.`LocalName` AS `LocalName`,`Country`.`GovernmentForm` AS `GovernmentForm`,`Country`.`HeadOfState` AS `HeadOfState`,`Country`.`Capital` AS `Capital`,`Country`.`Code2` AS `Code2` from `Country` IGNORE INDEX (`p_c`) IGNORE INDEX (`p`) order by `Country`.`Population` limit 10"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "`Country` IGNORE INDEX (`p_c`) IGNORE INDEX (`p`)",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"rows_estimation": [
{
"table": "`Country` IGNORE INDEX (`p_c`) IGNORE INDEX (`p`)",
"table_scan": {
"rows": 239,
"cost": 9
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`Country` IGNORE INDEX (`p_c`) IGNORE INDEX (`p`)",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 239,
"access_type": "scan",
"resulting_rows": 239,
"cost": 56.8,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 239,
"cost_for_plan": 56.8,
"chosen": true
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": null,
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "`Country` IGNORE INDEX (`p_c`) IGNORE INDEX (`p`)",
"attached": null
}
]
}
},
{
"clause_processing": {
"clause": "ORDER BY",
"original_clause": "`Country`.`Population`",
"items": [
{
"item": "`Country`.`Population`"
}
],
"resulting_clause_is_simple": true,
"resulting_clause": "`Country`.`Population`"
}
},
{
"reconsidering_access_paths_for_index_ordering": {
"clause": "ORDER BY",
"index_order_summary": {
"table": "`Country` IGNORE INDEX (`p_c`) IGNORE INDEX (`p`)",
"index_provides_order": false,
"order_direction": "undefined",
"index": "unknown",
"plan_changed": false
}
}
},
{
"refine_plan": [
{
"table": "`Country` IGNORE INDEX (`p_c`) IGNORE INDEX (`p`)"
}
]
}
]
}
},
{
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`Country` IGNORE INDEX (`p_c`) IGNORE INDEX (`p`)",
"field": "Population"
}
],
"filesort_priority_queue_optimization": {
"limit": 10,
"rows_estimate": 939,
"row_size": 272,
"memory_available": 262144,
"chosen": true # The priority queue optimization applies
},
"filesort_execution": [
],
"filesort_summary": {
"rows": 11,
"examined_rows": 239,
"number_of_tmp_files": 0,
"sort_buffer_size": 3080,
"sort_mode": "<sort_key, additional_fields>"
}
}
]
}
}
]
}
| [1] | (1, 2) http://dev.mysql.com/doc/refman/5.7/en/order-by-optimization.html |